
一,深度优先搜索
基本思想:
以图中某个顶点Vi为出发点,首先訪问出发点Vi,然后任选一个Vi的未訪问过的临界点Vj,以Vj为新的出发点继续进行深度优先搜索,依此类推,直至图中全部顶点都被訪问过。
深度优先搜索能够看成一个递归过程。

详细过程:
首先选定结点v0为出发点,訪问V0。然后从V0的邻接点V1,V3,V5。任选一个訪问,此处我们訪问V1。V1有两个邻接点V0和V2,V0已经被訪问过。我们接着訪问V2; V2有3个邻接点。当中V1被訪问过。我们选择V3或者V4訪问,此处先訪问V4。到了V4这里,V4有3个邻接点V2,V3。V5,当中V2被訪问过,我们訪问V3。V3的邻接点都已訪问完,我们返回V4。接着訪问V5;至此,全部节点都已訪问完毕。
注意事项:
1,搜索到某个顶点时,假设这个顶点的全部邻接点都被訪问过,那么搜索就要回到前一个被訪问过的顶点,再从该顶点的下一个未被訪问的邻接点開始深度优先搜索;
2,深度优先搜素的顶点的訪问顺序不是唯一的;
二,广度优先搜索
基本思想:
从图中某个顶点Vi出发。在訪问了Vi之后依次訪问Vi的全部邻接点,然后依次从这些邻接点出发按广度优先索索方法遍历图的其它顶点,反复这一过程直至全部顶点被訪问到;
广度优先搜索类似于树的依照层次遍历的过程。
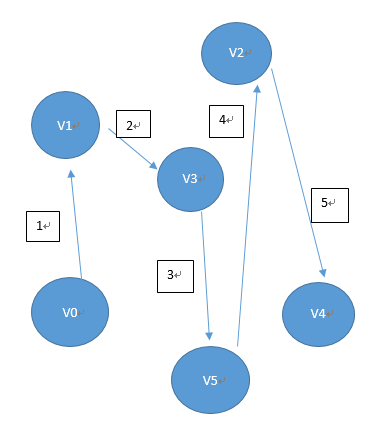
訪问过程:
首先从起点V0 出发,訪问V0.VO有3个未被訪问的邻接点V1。V3。V5;
先訪问V1。然后V3。最后V5。
然后訪问V1未被訪问的邻接点V2;
接着訪问V3未被訪问的邻接点V4;
小结:
在广度优先搜索中。若对X的訪问先于Y,则对于X的邻接点的訪问也先于Y进行。也就是说广度优先搜索邻接点的寻找具有先进先出的特征;
为了保证结点这样的先后的特征。能够採用队列来暂存那些刚訪问过的顶点。
版权声明:本文博客原创文章,博客,未经同意,不得转载。